Chapter 2 of the book delves into the concept of heterogeneous data parallel computing, primarily using CUDA C programming. It begins by explaining data parallelism and its significance in modern applications that handle massive amounts of data, such as image processing, scientific simulations, and molecular dynamics. The chapter then introduces the structure of a CUDA C program, demonstrating how to write a simple data parallel program using a vector addition example. It covers various aspects of CUDA programming, including memory management, kernel functions, threading, and the compilation process. The chapter aims to equip readers with the foundational knowledge to exploit data parallelism for faster execution on heterogeneous computing systems.
2.1 Data Parallelism
Data parallelism involves performing computation work independently on different parts of a dataset in parallel. This concept is crucial for applications dealing with large datasets, such as image processing, scientific simulations, and molecular dynamics. The chapter explains how to organize computations around data to execute independent computations in parallel, thus achieving faster execution. It uses the example of converting a color image to grayscale to illustrate data parallelism.
A great example is converting an RGB image to greyscale, to convert a RGB image to Grayscale we just need to run a formula: for each pixel. It follows that as each pixel only requires the data of itself, it can be run in parallel to other pixels’ calculation
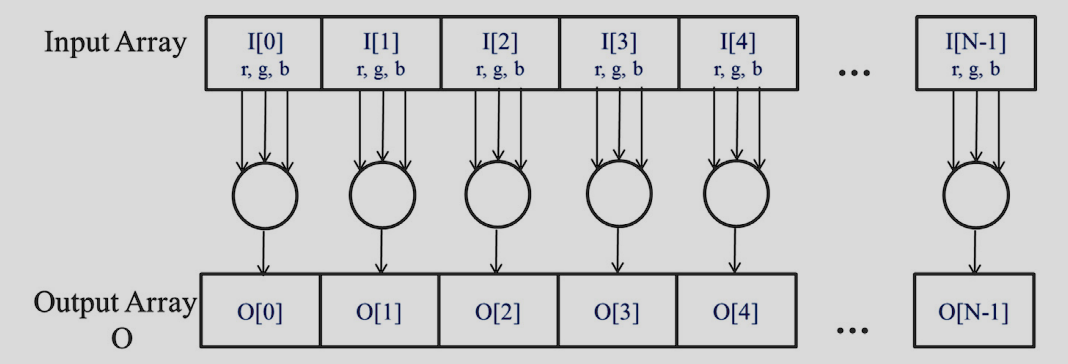
Task vs Data Parallelism
Data parallelism is not the only type of parallelism used in parallel programming. Task parallelism has also been used extensively in parallel programming. Task parallelism is typically exposed through task decomposition of applications. For example, a simple application may need to do a vector addition and a matrix-vector multiplication. Each of these would be a task. Task parallelism exists if the two tasks can be done independently. I/O and data transfers are also common sources of tasks. In large applications, there are usually a larger number of independent tasks and therefore larger amount of task parallelism. For example, in a molecular dynamics simulator, the list of natural tasks includes vibrational forces, rotational forces, neighbor identification for non-bonding forces, non-bonding forces, velocity and position, and other physical properties based on velocity and position. In general, data parallelism is the main source of scalability for parallel programs. With large datasets, one can often find abundant data parallelism to be able to utilize massively parallel processors and allow application performance to grow with each generation of hardware that has more execution resources. Nevertheless, task parallelism can also play an important role in achieving performance goals. We will be covering task parallelism later when we introduce streams.
2.2 CUDA C Program Structure
CUDA C extends ANSI C with minimal syntax and library functions to target heterogeneous computing systems containing both CPU cores and GPUs.
A CUDA C program consists of host code (executed by the CPU) and device code (executed by the GPU).
The execution starts with the host code (CPU serial code), and when a kernel function is called, a large number of threads are launched on the device to execute the kernel. All the threads that are launched by a kernel call are collectively called a grid When all threads of a grid have completed their execution, the grid terminates, and the execution continues on the host until another grid is launched.

2.3 A Vector Addition Kernel
Before developing Kernel code, we can first analyse the traditional host based code for vector addition:
// Compute vector sum C_h = A_h + B_h
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
for (int i = 0; i < n; ++i) {
C_h[i] = A_h[i] + B_h[i];
}
}
int main() {
...
vecAdd(A, B, C, N);
}The naming convention for CUDA/Parallel coding is that we use _h to denote host variables, and _d for device variables. In the case above, as we have no device code, there is only _h variables.
A straightforward way to execute vector addition in parallel is to modify the vecAdd function and move its calculations to a device.
void vecAdd(float* A, float* B, float* C, int n) {
int size = n* sizeof(float);
float *d_A *d_B, *d_C;
// Part 1: Allocate device memory for A, B, and C
// Copy A and B to device memory
...
// Part 2: Call kernel – to launch a grid of threads
// to perform the actual vector addition
...
// Part 3: Copy C from the device memory 14
// Free device vectors
...
}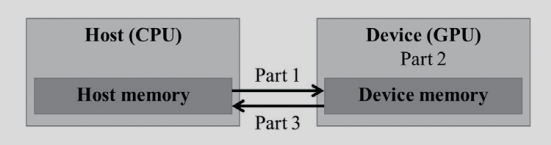
Note that the revised vecAdd function is essentially an outsourcing agent that ships input data to a device, activates the calculation on the device, and collects the results from the device.
The agent does so in such a way that the main program does not need to even be aware that the vector addition is now actually done on a device. In practice, such a “transparent” outsourcing model can be very inefficient because of all the copying of data back and forth. One would often keep large and important data structures on the device and simply invoke device functions on them from the host code.
For now, however, we will use the simplified transparent model to introduce the basic CUDA C program structure.
2.4 Device Global Memory and Data Transfer
In CUDA, devices have their own dynamic random-access memory called device global memory.
For our vecAdd kernel, we need to allocate space in the device global memory
cudaMalloc()
- Allocates objects in the device global memory
- Two Paramters
- Address of pointer to allocated object should be cast to (void **)
- Size of allocated object in bytes
cudaFree()
- Frees objects from device global memory
- One Parameter
- Pointer to freed object
More on cudaMalloc():
Our pointer address variables should be cast to void ** i.e a generic pointer as the memalloc should be a generic function unrestricted by type.
This parameter allows the funciton to write the address of the allocated memory into the provided poitner variable regardless of its type.
This means we can use these two functions as such:
float *A_d
int size = n*sizeof(float);
cudaMalloc( (void**)&A_d, size);
...
cudaFree(A_d);cudaMemcpy()
- data transfer from memory
- Requires four parameters
- Pointer to dest
- Pointer to source
- Number of bytes copied
- Type/Direction for Transfer (H2D, D2H, D2D, H2H)
Extending the previous code we can get:
float *A_d, *B_d, *C_d
int size = n * sizeof(float);
cudaMalloc( (void**)&A_d, size);
cudaMalloc( (void**)&B_d, size);
cudaMalloc( (void**)&C_d, size);
cudaMemcpy(A_d, A_h, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B_h, size, cudaMemcpyHostToDevice);
...// Kernel Invocation code
cudaMemcpy(C_d, C_h, size, cudaMemcpyDeviceToHost);
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
Error Checking & Handling
In practice we should handle potential memory allocation errors with mallocs: Such as:
cudaError_t err = cudaMalloc((void**) &A_d, size);
if(error != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err), __FILE__, __LINE__);
exit(EXIT_FAILURE);
}One could even define a C macro to make this more concise in the source code
2.5 Kernel Functions and Threading
Kernel functions in CUDA C specify the code to be executed by all threads during a parallel phase. The chapter introduces the concept of single-program multiple-data (SPMD) programming and explains how threads are organized into blocks and grids. It discusses built-in variables like threadIdx, blockIdx, and blockDim, which allow threads to distinguish themselves and determine the area of data each thread works on.
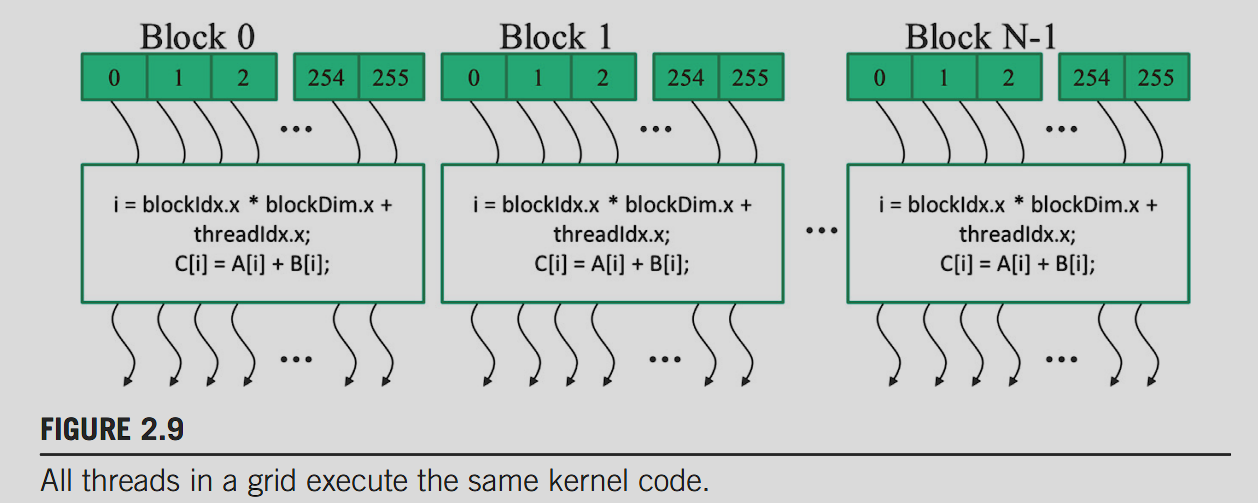
In this one dimensional example we can define our global thread index as:
i = blockIdx.x * blockDim.x + threadIdx.xSince each thread uses i to access A,B,C these threads can therefore cover the first 768 iterations of the original loop. By launching a grind with a larger number of blocks we can process larger vectors, more concretely, by launching a grid with n or more threads, we can process vectors of length n.
The following code is a kernel function for vector addition:
__global__
void vecAddKernel(float* A, float* B, float* C, int n) {
int i = threadIdx.x + blockDim.x * blockIdx.x
if (i < n) {
C[i] = A[i] + B[i];
}
}Note that as we are executing on the device, we dont need _h or _d as there cannot be confusion.
We use the keyword __global__ to indicate the function is a kernel and that it can be called to generate a grid of threads on a device. This kernel funciton is executed on the device and called form the host
| Qualifier Keyword | Callable From | Executed On | Executed By |
|---|---|---|---|
| _host_ (default) | Host | Host | Caller host thread |
| _global_ | Host (or Device) | Device | New grid of device threads |
| _device_ | Device | Device | Caller device thread |
| A device function executes on a CUDA device and can only be called from a kernel function or another device function. It will never result in new device threads being called. |
2.6 Calling Kernel Functions
Finally with all our kernel function implemented/designed, we need to call that function somehow from the host code in a way to launch the grid.
// Launch ceil(n/256) blocks of 256 threads each
vecAddKernel<<<ceil(n/256.0), 256>>>(A_d, B_d, C_d, n);This code sets the grid and thread block dimensions, which are called configuration parameters inside the ”<<<” ”>>>”, before passing the parameters in as standard C. The first parameter specifies the number of blocks in the grid, and the second the number of threads in each block.
We define each block to be a flat 256 threads here, and to make sure we have enough threads to cover all elements of our vector, we use enough grids such that all N items can fit inside
The full function then for the host vecAdd would be as such:
void vecAdd(float* A, float* B, float* C, int n) {
float *A_d, *B_d, *C_d;
int size = n * sizeof(float);
cudaMalloc((void **) &A_d, size);
cudaMalloc((void **) &B_d, size);
cudaMalloc((void **) &C_d, size);
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);
vecAddKernel<<<ceil(n/256.0), 256>>>(A_d, B_d, C_d, n);
cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost);
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
}Note that blocks dont have to all happen in any particular order, or even in parallel, in some cases the GPU does not have enough threads, and will only run a few blocks at a time in parallel, so it’s very important to not make assumptions on order
2.7 Compilation
CUDA C programs require a specialized compiler that understands CUDA extensions. The chapter introduces the NVIDIA C compiler (NVCC), which processes CUDA C programs by separating host code and device code. The host code is compiled with standard C/C++ compilers, while the device code is compiled into virtual binary files called PTX files, which are further compiled into real object files and executed on a CUDA-capable GPU.
2.8 Summary
The chapter provides a summary of the core concepts and CUDA extensions discussed, including function declarations, kernel call and grid launch, built-in variables, and the runtime application programming interface. It emphasizes the importance of understanding these extensions to write effective CUDA C programs for parallel computing.
Questions
1c 2c 3d 4c 5d 6d 7c 8c 9a: 128 b: 200,064 c: 1563 d: 200,000 e: 64 10: You can allocate both __host__ and __device__ above a function