Why?
- Data persistence* (lasts between boots, unlike RAM)
- Data organization (structure etc)
- Metadata
- Protection (Access Permissions)
Metadata (File Attributes)
Name – only information kept in human-readable form Identifier – unique tag (number) identifies file within file system Type – needed for systems that support different types Location – pointer to file location on device Size – current file size Protection – controls who can do reading, writing, executing Time, Date, and User Identification – data for protection, security, and usage monitoring
Information about files are kept in the directory structure, which is maintained on the disk
OS File Management
Logical File System (LFS) handles metadata
- Metadata Management
- Translates file name into file number, file handle, location by maintaining file
- Uses control blocks like inodes in Unix systems
- Directory and Protection
- Responsible for directory management, and hierarchical file organisation.
- Enforces file access permissions
This is very useful for reducing complexity and redundancy, but adds overhead which affects performance
Typically an OS can support multiple file systems, allowing for flexibility in addressing diff storage needs and structures
File Operations
A file is an abstract data type
Create
Write - at write pointer location - fwrite
Read - at read pointer location - fread
Reposition within file - fseek
Delete - remove
Truncate - ftruncate
Open(Fi) - search the directory structure on disk for entry Fi and move the content of entry to memory - fopen
Close(Fi) - move the content of entry Fi in memory to directory structure on disk - fclose
Open Files
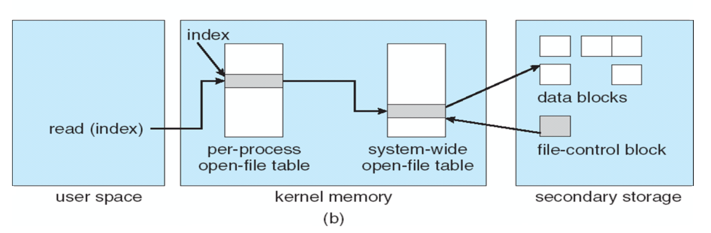
A open file table is used to track per-process opened files Each per-process file handle has a pointer to the location for reading/writing in the file
Access rights - per process (read/write etc..)
lsof utility in Linux (List Open Files)
File Structures
None
This is like a text file, a sequence of words, or bytes
Simple Record Structure
- Lines (e.g. log file)
- Fixed Length (e.g. CSV)
- Variable Length (e.g. JSON)
Complex Structures
- Formatted Documents (e.g. LaTeX documents)
- Relocatable Load File (e.g. C object file)
File Access
Sequential Access
Simplest form, access byte-by-byte from the start to the end
Direct Access
Given a fixed record structure, we can seek to offset N and know that the Nth record will be there
Side-Index
This is used in more complex files, like databases
Access Control
The file owner/creator should be able to control what can be done to the file, and by whom.
Types of access:
- Read
- Write
- Execute
- Append
- Delete
- List
Unix File Permissions
+---+---+---+
| 1 | 1 | 1 |
+---+---+---+
| | |
read | |
write |
execute
So a three-bit permission set. Value range from 0→7
There are three sets of permissions.
- User
- Group
- Other
This makes 9 permission bits total
Mounting
For a file system to be accessed it must first be mounted
An unmounted file system is mounted at a mount point
(/mnt in Unix, or a new Drive letter in Windows)
Consider for example the functioning of a USB drive
Directories
Why Use Directories?
Efficiency → Organisation and locating of files Grouping → Logical collections of files, ordered in the same location Naming → Files are able to have the same name provided they are in different dirs
Directory Operations
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
Types
Tree-Structured Directory
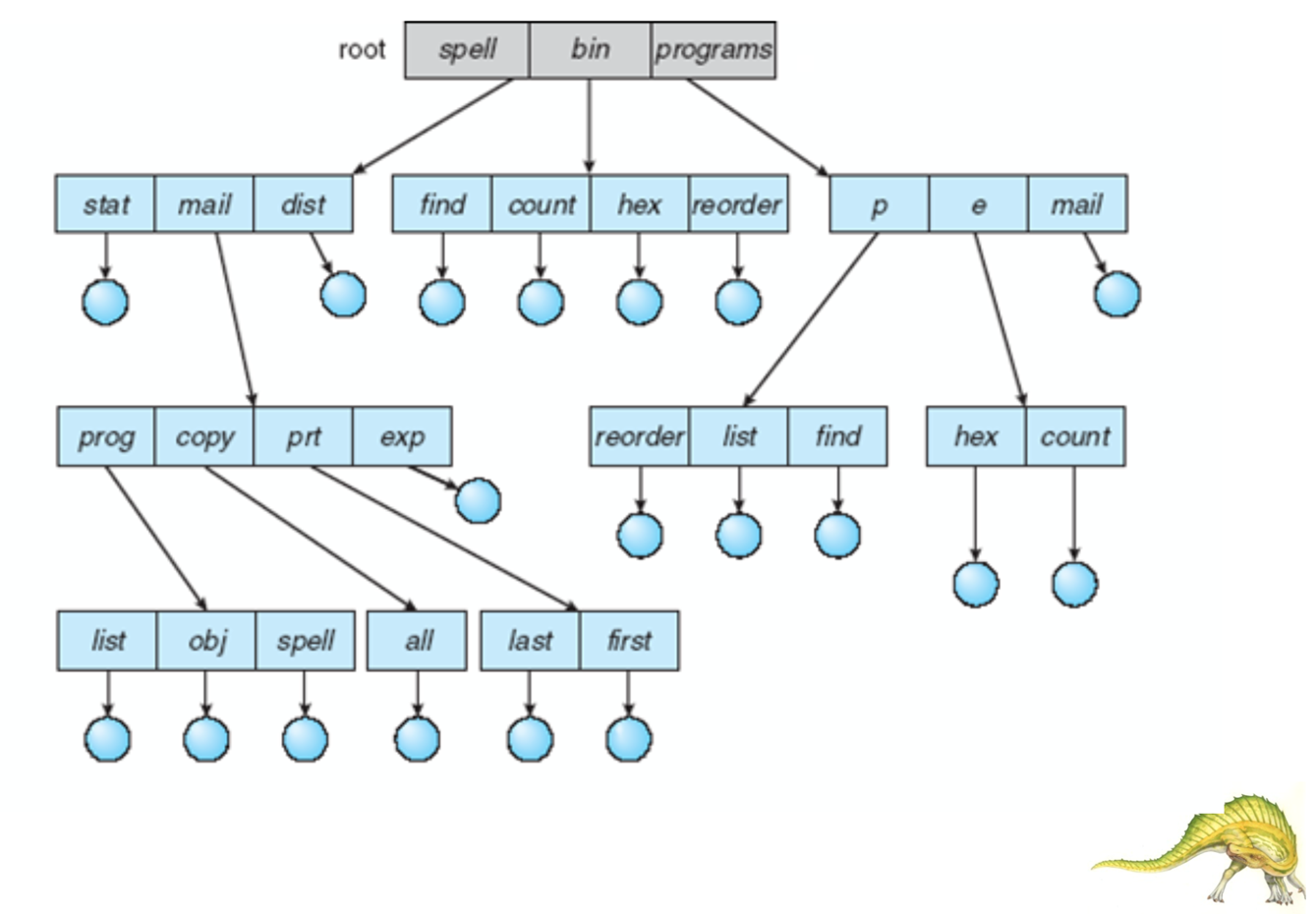
This allows us to have efficient searching and grouping, as well as the notion of a “working directory”. The use of a tree allows us not just to have relative, but absolute pathnames We can create and delete subdirectories
DOS, and early windows systems have tree-structured directories
Acyclic Graph Directory
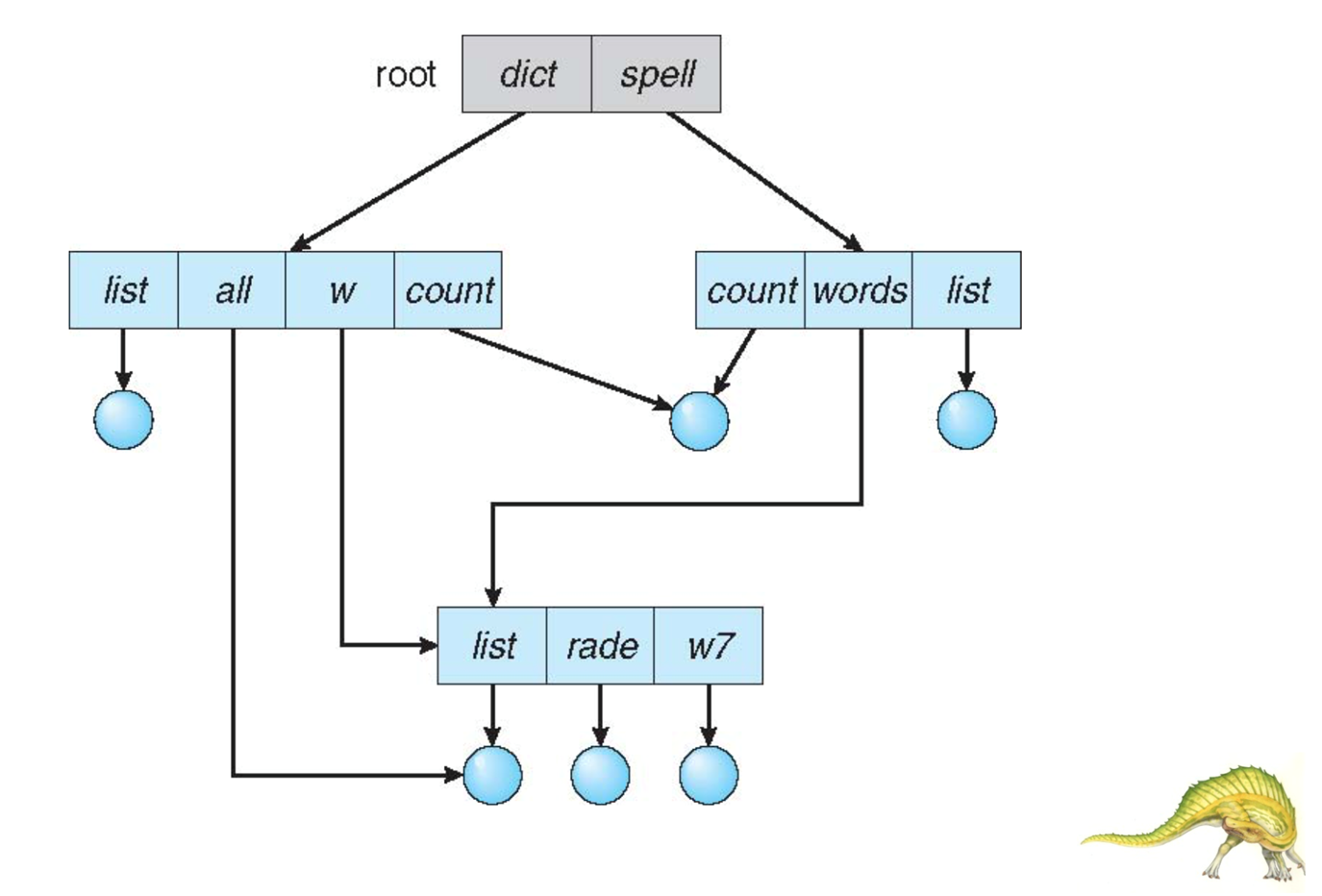
The same file can have multiple names (that point to it) This means that directories contain links to files (i.e. pointers)
Reference counting is used to ensure safe deletion
Use of ln to create new link to an existing file
Featured in UNIX systems
Dangling Pointers
Soft links in Unix (ln -s), or shortcuts in Windows Delete original file, then soft link is broken
Directory Implementation
Linear list of file names with pointer to the data blocks
- Simple to program
- Time-consuming to execute
- Linear search time
- Could keep ordered alphabetically via linked list or use B+ tree Hash Table – linear list with hash data structure
- Decreases directory search time
- Collisions – situations where two file names hash to the same location
- Only good if entries are fixed size, or use chained-overflow method
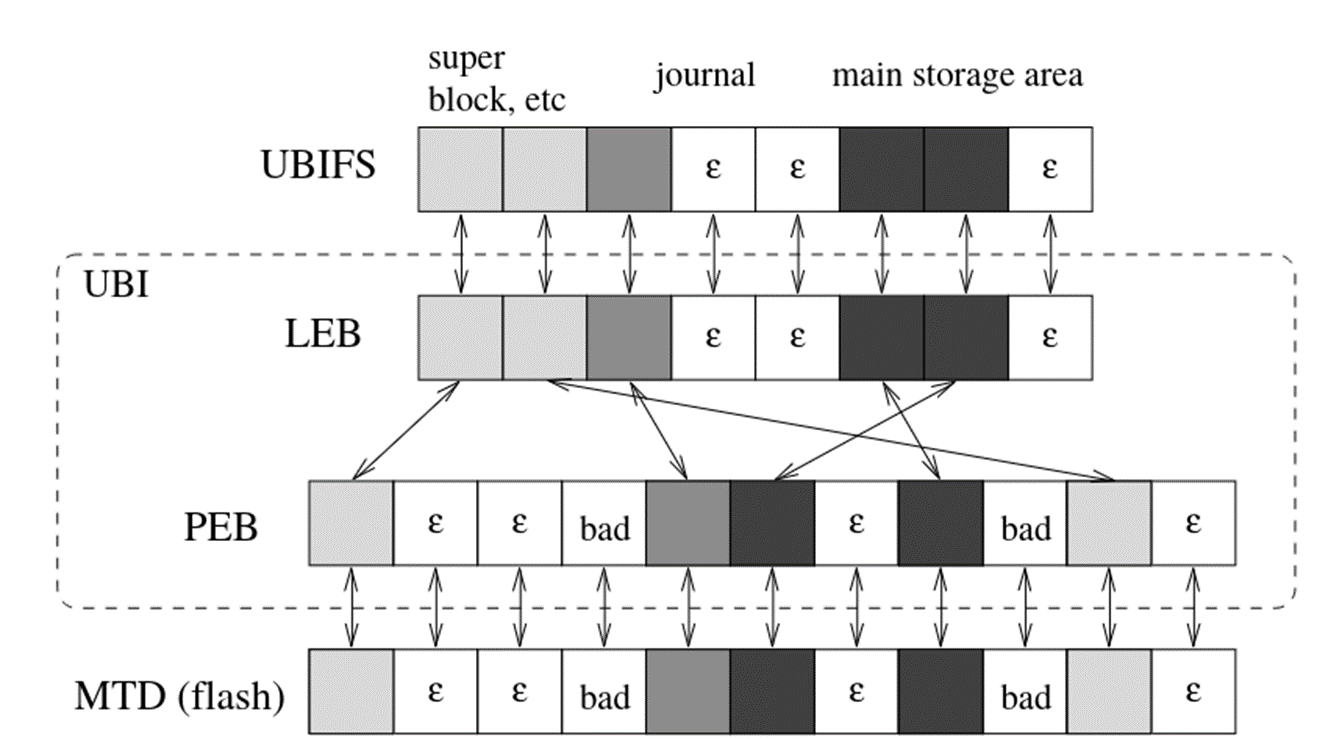
Mass Storage Devices
These are typically a flash memory chip with some form of controller
NOR
This is faster to read, uses one-byte random access, and is used for things like bootloaders and direct execution of code, but is more expensive, though this translates to lasting longer as well
NAND
This uses block level access, which is slower, and requires caching mechanisms to improve data access speed, and has factors like wear levelling which lead it to require error correction, however it is much cheaper
Error Correction and Wear Levelling
File System Data Structures
How do we implement the systems calls at the API level?
- On-disk and In-memory Structures
- These structures are fundamental to the file system. On-disk structures are stored directly on the storage device and contain critical information required for the system’s operation, such as booting up the OS. In-memory structures reside in volatile memory (RAM), facilitating quicker access and efficient management of files during system operation.
- Boot Control Block
- This is a specific on-disk structure that contains information necessary for the system to start up, or “boot.” It generally includes the code to initiate the boot process and is usually found in the first block of a storage volume. If the volume contains an operating system, the boot control block is essential.
- Volume Control Block (Superblock/Master File Table)
- This critical data structure contains all the metadata about the file system’s volume, such as the number of blocks in the volume, the number of free blocks available, the size of each block, and pointers or an array indicating the free blocks. It’s often the starting point for the file system to locate files and manage storage space.
- Directory Structure
- The directory structure is how the file system organizes and provides a hierarchical view of the files. It includes the mapping of file names to inode numbers and the master file table, which can be thought of as a central directory listing all files.
- File Control Block (FCB)
- Each file in the system has a corresponding FCB, which stores detailed information about the file, such as its inode number (a unique identifier), permissions (who can read, write, or execute the file), the size of the file, and timestamps that record creation, modification, and last access times.
NTFS and Relational Database Structures
- The NTFS (New Technology File System) utilized by Windows operating systems stores file information in a master file table, similar to a relational database. This allows complex relationships between files and directories, facilitating advanced features like security descriptors, file compression, and encryption.
Example File Control Block
- File Permissions
- File Dates (Create, Access, Write)
- File Owner, Group, ACL
- File Size
- File Data Blocks, or pointer to File Data Blocks
Opening a File
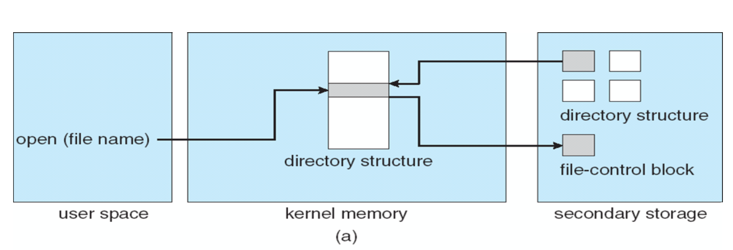
Accessing a File
Virtual File Systems (VFS)
VFS on Unix provides an object-oriented way of implementing file systems VFS allows the same system call interface (the API) to be used for different types of file systems.
- Separates files-system generic operations from details of implementation
- Implementation can be one of many file systems types, or network file The system:
- Implements vnodes which hold inodes, or network file details
- Then dispatches operation to appropriate file system implementation routines