A property of the system: more than one CPU core allows execution of tasks in parallel Similarly, hardware support for parallel instructions If the kernel supports hardware parallelism, it will try to speed up the execution of tasks by making use of the available parallel resources.
Linux Kernel Support
SMP boot process
Symmetric multiprocessing (SMP). What this means is that every compute unit runs a separate scheduler, and there are mechanisms to move tasks between scheduling queues on different compute units. The boot process is, therefore extended from the boot sequence discussed in Lecture 2.
Essentially, the kernel boots on a primary CPU and when all common initialization is finished, the primary CPU sends interrupt requests to the other cores which result in running secondary_start_kernel() .
Load Balancing
The main mechanism to support parallelism in the Linux kernel is automatic load balancing, which aims to improve the performance of SMP systems by offloading tasks from busy CPUs to less busy or idle. The Linux scheduler regularly checks how the task load is spread throughout the system and performs load balancing if necessary
Processor affinity control
The functionality used to move tasks between CPUs is exposed to the user as affinity control through a POSIX API. These calls control the thread’s CPU affinity mask, which determines the set of CPUs on which it can be run. On multicore systems, this can be used to control the placement of threads. This allows user-space applications to take control over the load balancing instead of the scheduler.
ARM Hardware Support
With the advent of systems like Arm’s big.LITTLE
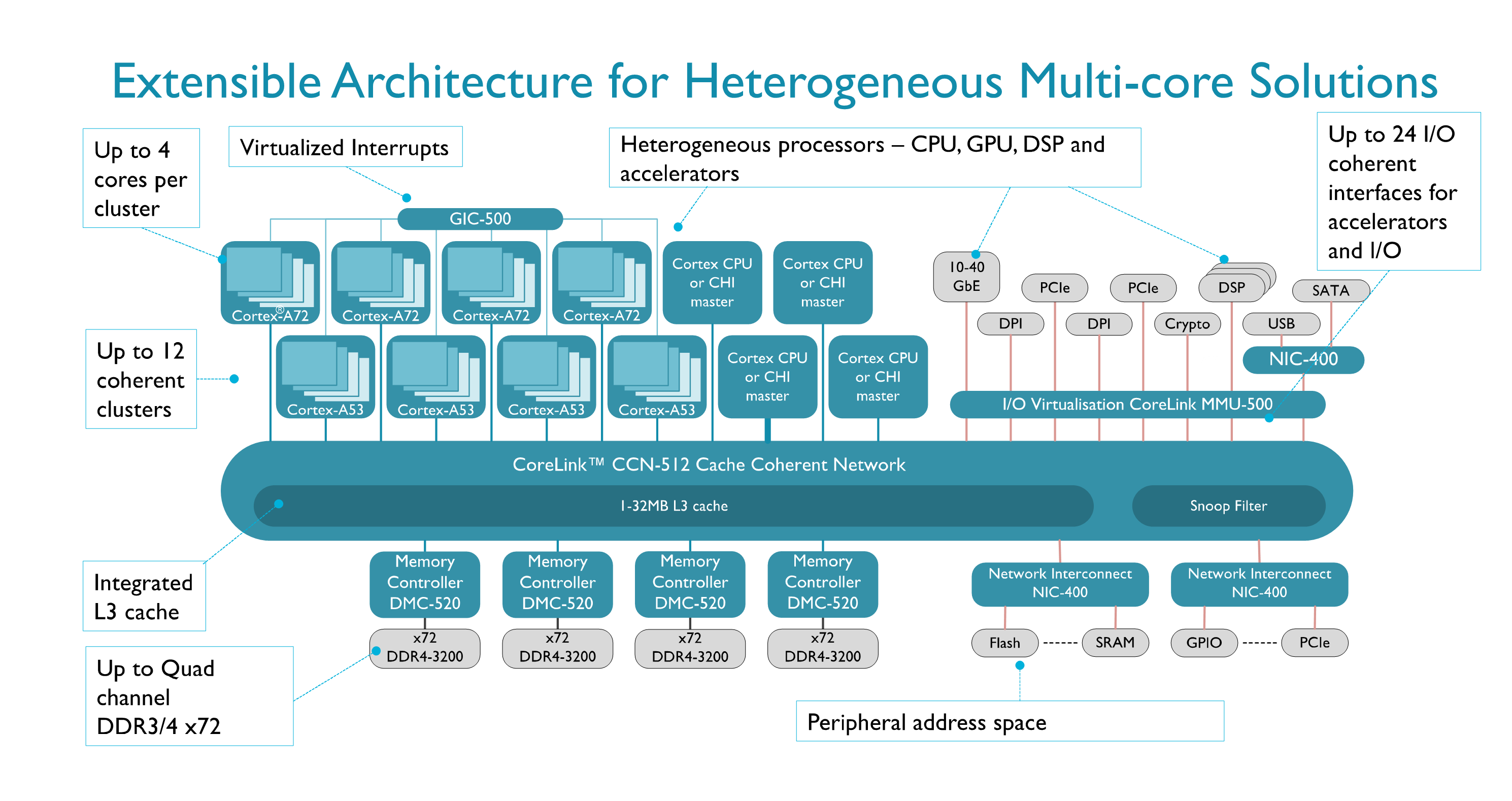 (with “big” A72 cores and “little” A53 cores), the SMP model is no longer adequate, because tasks will spend a much longer time running if they are scheduled on a “little” core than on a “big” core. Therefore efforts have been started towards “global task scheduling” or “Heterogeneous multiprocessing” (HMP), which require modifications of the scheduler in the Linux kernel. When a processor comprises multiple processing cores, the hardware must be designed to support parallel processing on all cores. Apart from supporting cache-coherent shared memory and the features to support concurrency as discussed above, there are a few other ways in which Arm multicore processors support parallel programming.
(with “big” A72 cores and “little” A53 cores), the SMP model is no longer adequate, because tasks will spend a much longer time running if they are scheduled on a “little” core than on a “big” core. Therefore efforts have been started towards “global task scheduling” or “Heterogeneous multiprocessing” (HMP), which require modifications of the scheduler in the Linux kernel. When a processor comprises multiple processing cores, the hardware must be designed to support parallel processing on all cores. Apart from supporting cache-coherent shared memory and the features to support concurrency as discussed above, there are a few other ways in which Arm multicore processors support parallel programming.
SIMD (Single Instruction Multiple Data) or Vector Processing
→ Does not require intervention from the OS as it is instruction-based per-core parallelism.
Multi-Core-Aware
→ The Arm Generic Interrupt Controller Architecture provides support for software control the delivery of hardware interrupts to:
- a particular processing element (“Targeted distribution model”)
- one PE out of a given set (“1 of N model”);
- control the delivery of software interrupts to multiple PEs (“Targeted list model”).
Multiprocessor Affinity Register (MPIDR)
→ Allows the OS to identify the PE on which a thread is to be scheduled.
YIELD
→ Used to indicate to the PE that it is performing a task that could be swapped out to improve overall system performance. The PE can use this hint to suspend and resume multiple software threads
SEV
→ Causes an event to be signaled to all PEs in the multiprocessor system. A PE sets the Event Register on that PE. The Event Register can be used by the Wait For Event (WFE) instruction. If the Event Register is set, the instruction clears the register and completes immediately; if it is clear, the PE can suspend execution and enter a low-power state
Challenges?
The main challenge in exploiting parallelism is in a way similar to scheduling: we want to use all parallel hardware threads in the most efficient way. From the OS perspective, this means control over the threads to run on each compute unit.
But whereas scheduling of threads/processes means multiplexing in time, parallelism effectively means the placement of tasks in space. The Linux kernel has for a long time supported symmetric multiprocessing (SMP), which means an architecture where multiple identical compute units are connected to a single shared memory, typically via a hierarchy of fully-shared, partially-shared and/or per-compute-unit caches. The kernel simply manages a scheduling queue per core.