Abstract
In computing a process can be thought of as a program in execution If a program is like a Class, then a process is like the Object
Processes are both entities of Scheduling]] and of Ownership, a OS schedules multiple
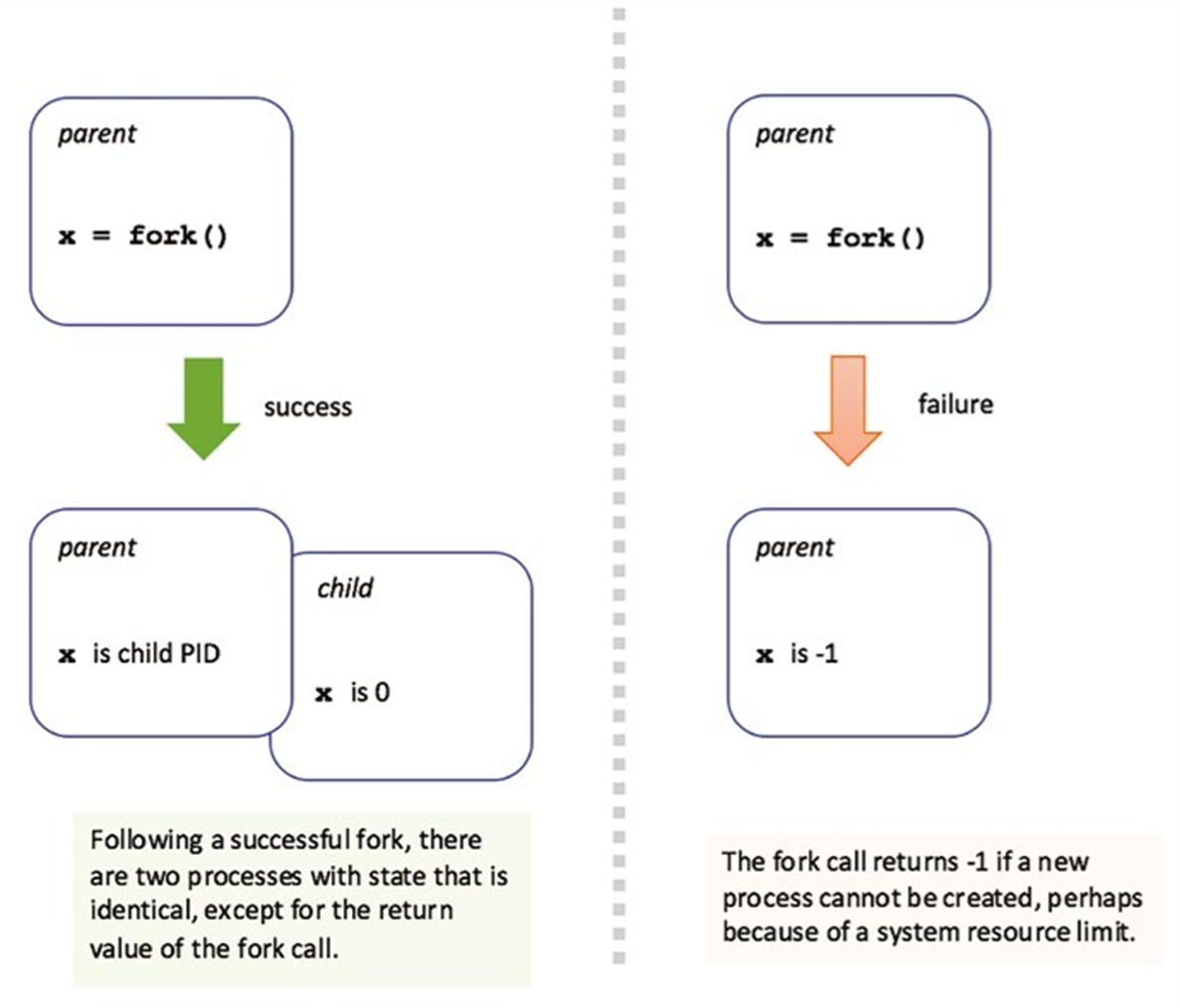
Launching a New Process: fork()
The system call to create new processes is called fork().
When you start a process from the command line, the shell is the parent process and the process you start is the child.
The child process:
- is a copy of the parent process, with the only difference being the return value
of the fork() call. - occupies an entirely separate virtual address space
So any subsequent changes made to either the parent or the child memory will not be visible in the other process.
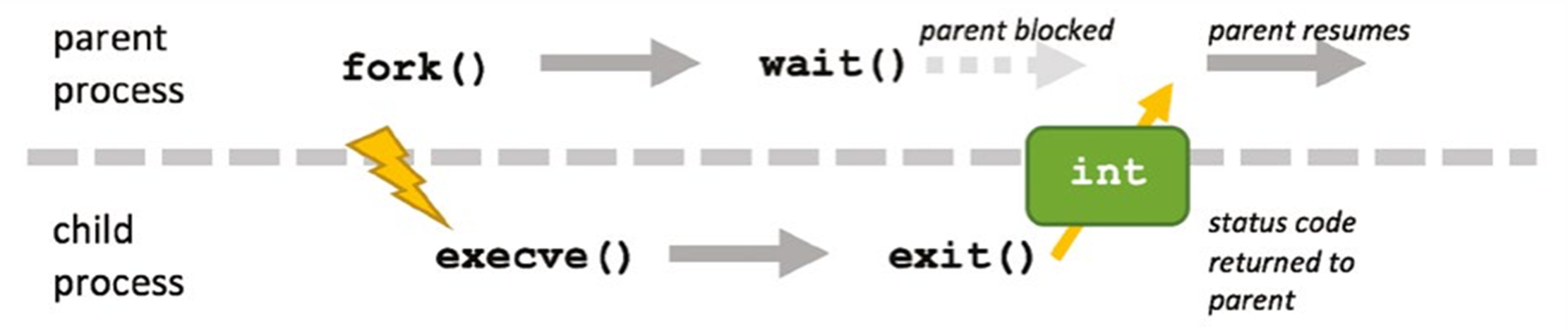
Doing Something Different: execve()
The fork syscall allows us to start a new process, but the child is a replica of the parent.
To execute a different program in a child process, Linux provides the execve() system call, which replaces the currently running process with data from a specified program binary.
- The first parameter is the name of the executable file,
- The second parameter is the argument vector (effectively argv in C programs), and
- The third parameter is a set of environment variables, as key/value pairs.
Ending a Process: wait(), exit()
When it has created a child with the fork() call, a parent process can block, waiting for a child process to complete, using the wait() call
Like any process, a child process normally exits by returning from its main routine
But a child process can also complete by calling the exit() function
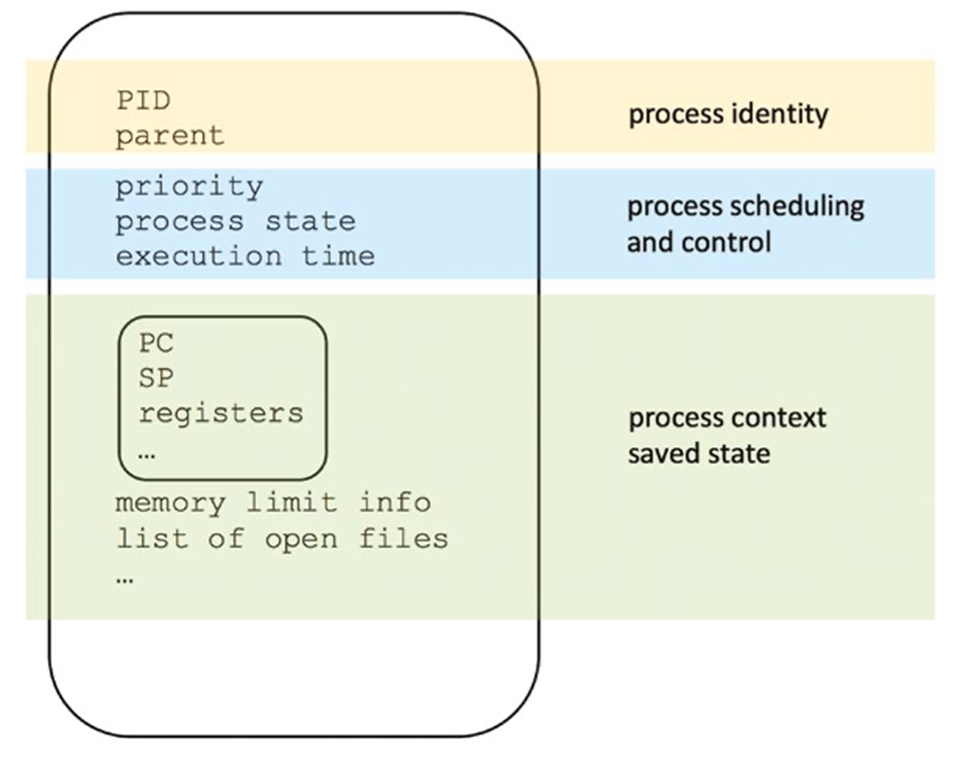
Process Metadata
Each process has metadata associated with it. The OS requires this metadata to identify, execute, and manage each process.
Generally, the relevant information is encapsulated in a data structure known as a process control block (PCB).
The most basic metadata is the unique, positive integer identifier associated with a process, conventionally known as the process pid.
getpid() function from unistd.h
The Linux kernel uses three data structures to keep track of the process information thread_info and thread_struct: processor-specific context task_struct: all the context for the process
Process Hierarchies: process tree descended from init process
Some metadata is related to context switch saved data, such as register values, open file handles, or memory configuration.
- This information enables the process to resume execution after it has been suspended by the OS.
Further metadata relates to the interactions between a process and the OS—e.g., profiling statistics and scheduling details.
In /proc/
The Linux kernel exposes some process metadata as part of a virtual file system, in the /proc directory
For example:
cmdline - The textual command that was invoked to start this process
cwd - A symbolic link to the current working directory for this process
exe - A symbolic link to the executable file for this process
fd/ - A folder containing file descriptors for each file opened by the process
maps - A table showing how data is arranged in memory
stat - A list of counters for various OS events, specific to this process
the full list is documented in the man page for /proc The entries in /proc/ are not ‘real’ files —look at the file sizes with ls -l. They are file-like representations of in-memory kernel metadata for each process.
Process Behaviour
Typically a process has …
- CPU bursts: time the process uses CPU cycles
- I/O bursts: time the process waits for a resource e.g: user input, file access, data from memory, data to arrive through network etc
- CPU intensive process - e.g. bitcoin miner, MP3 encoder
- IO intensive process - e.g. disk formatter, web server
Note: CPU burst is generally shorter than I/O burst Most jobs require very few milliseconds of CPU access to run commands. Less than 10% needs more than 8ms.