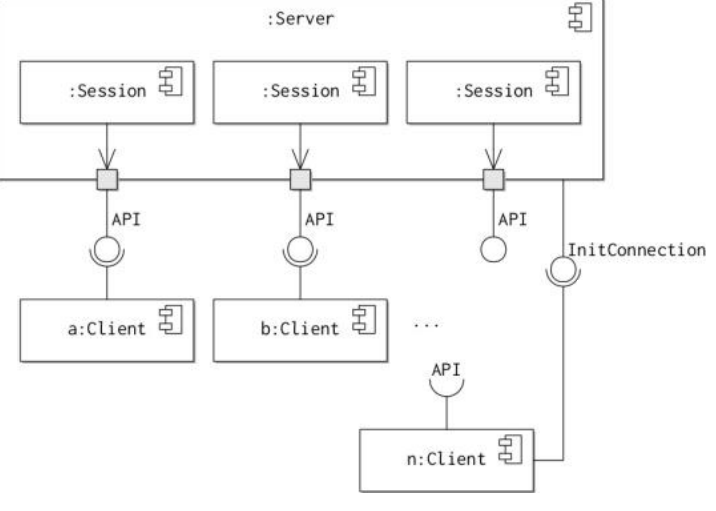
The client-server pattern embodies this philosophy at an architectural level by collating the management of information and services into a centralised server. The component diagram shows a snapshot of the state of a client server system.
The server is responsible for providing access to information or services it hosts to one or more clients through a common interface. The server is also responsible for ensuring the integrity of the information it stores by validating change requests from clients.
The client is responsible for presenting information gathered from the server to end-users and for issuing commands to the server. The end-users may be people or other software components.
In a client-server system, there are two interfaces. The first interface is used by the client to indicate that it wishes to establish a new connection with the server in order to communicate. A separate session is established each time a client connects to the server. This arrangement allows the server to handle multiple connections from many clients simultaneously. The server exports a second type of interface, the main API. This interface specifies the messages that can be sent once a connection has been established between client and server. Note that the state of a connection is maintained by the session responsible for that connection.
There are many examples of the client-server architectures and standards in software engineering, particularly for network applications such as web servers, SSH, instant messaging etc.
Thin vs Fat Clients
*There are two major sub-flavours of the client-server pattern: *
Thin client architectures are the classical or purists approach to the client server pattern. The clients are sometimes referred to as dumb clients or terminals, because they contain very little program logic. All information and as much functionality as possible is collected into the server. The client has very limited functionality and is responsible only for issuing instructions to the server and displaying results. Even decisions about how to present information to the user may be controlled by the server.
Fat client architectures take the reverse approach, devolving much more responsibility for information management, validation, processing and storage to the clients themselves. Fat client architectures can be useful because they can reduce the amount of communication required between the client and the server by caching some information in the client. In addition, some of the processing is delegated to the clients, reducing computational demands on the server.
-
As can be seen, there is a trade-off to be made between a thin or fat client architecture for a system. Devolving responsibility to the clients reduces load on the server, but also risks introducing inconsistencies in stored data and means that the clients have to be updated more frequently as software defects are discovered.
-
Fat client architectures have become more popular as processing capabilities of client environments have improved. This has enabled the development of richer and more interactive client user interfaces, which often need to cache more information. For example, web applications now often exploit the JavaScript capabilities of modern browsers to deliver responsive web applications.
Limitations of C-S Pattern
There are a number of limitations to the client-server pattern:
- Communication between servers and clients may suffer from unacceptable latency. This means that it takes too long for the server to receive commands, or for the client to receive a response. This problem can be mitigated by the clients caching some of the information received from the server (see the description of fat clients above).
- The scalability of the architecture is bounded by the physical resources (computational power, network bandwidth, memory) available to the server. This limitation is inevitable because the server acts as a single point of reference for all clients: the demands on the server grow as the number of clients increase. This problem is exhibited by the ease with which websites can be disabled by denial of service attacks. In the simplest case, an attacker directs as many clients as possible to request the same webpage from a site at the same time.
- The single point of reference in the architecture (the server) is also a single point of failure. If the server is disabled, then the entire system ceases to function. This problem can be mitigated by preparing fall-back servers, however, this then re-introduces the problem of ensuring consistency between multiple copies of the same data items or services. As a consequence, other architectural patterns have been developed that provide for greater scalability and redundancy.