DevOps - the integration of development and operations teams and workflows within software organisations.
Development to Operations
Development:
- Gathering requirements
- Adding features
- Quality assurance
- Defect resolution
→→→ RELEASE →→→
Operations:
- Infrastructure maintenance
- Deployment
- Monitoring
- User support
- Defect reporting
The development team are responsible for building and maintaining the application code base. This will involve:
- gathering requirements from stakeholders,
- developing new features,
- undertaking QA
- investigating and resolving defects.
However, the development team is responsible for actually deploying the application to real users in production. They will build the infrastructure such as servers and networking on which the application will run. This may involve negotiation with third parties, such as ISPs
Preparing for Release Handoff
Preparing for a release handoff involves several critical steps and collaboration between the development and operations teams to ensure a smooth transition to production. Here’s a detailed breakdown of the preparation process:
Release Preparation Steps
-
Installation and Configuration Guide:
- Create comprehensive guides that include a summary of new features and known defects, commonly referred to as release notes.
-
Code and Artifact Packaging:
- Compile and package the code, which may include binaries or automated installers, along with essential elements like configuration file templates and database migration scripts.
-
Acceptance Test Plan:
- Develop a detailed acceptance test plan to verify that the application functions correctly in the production environment.
-
Rollback Plan:
- Prepare a contingency plan for rolling back the release if critical defects are identified during acceptance testing.
Collaboration with Operations
- Deployment Discussions: Engage in ongoing discussions with the operations team about deployment strategies, including the placement of components within the production environment.
- Infrastructure Updates: Determine if the existing infrastructure needs updates or modifications to support the new release.
- Rehearsal: Practice the deployment process in a test environment, including any necessary rollback procedures.
Deployment Considerations
- Environment Configuration: Ensure the operations team configures the new release based on the provided instructions but tailored with production-specific details like database credentials and SSL certificates.
- Issue Reporting and Resolution: Any deployment issues should be reported, triaged, and resolved by the development team.
- Timing and Scheduling: Choose release dates carefully to avoid high-risk periods, such as major holidays or end-of-year activities when staff availability may be reduced.
- Support Readiness: The development team might need to work extended hours around the release date to support the operations team during the deployment process.
Post-Release Activities
- Defect Triage and Resolution: After the release, the development team should be prepared to address any defects that users encounter as they begin to explore and utilize the new features in varied and unforeseen ways.
By following these structured steps and maintaining close coordination between the development and operations teams, organizations can minimize disruptions and ensure successful software release handoffs.
Extending Continuous Integration to Ops
DevOps extends this concept by incorporating deployment and operations processes into the development life-cycle. This means that deployment mechanism become incorporated into the build process. It also means that greater emphasis on planning for the target infrastructure and quality assurance activities such as acceptance testing in the development cycle prior to release.
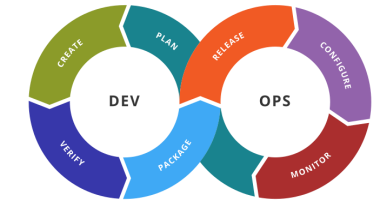 The diagram on the slide is one view of how DevOps integrates development and operations practices. The activities on the left are mostly familiar from what we have seen about software development.
However, it is important to stress that all these activities (planning, creation, verification, package) are done with explicit consideration of the infrastructure on which the software will be deployed.
The diagram on the slide is one view of how DevOps integrates development and operations practices. The activities on the left are mostly familiar from what we have seen about software development.
However, it is important to stress that all these activities (planning, creation, verification, package) are done with explicit consideration of the infrastructure on which the software will be deployed.
In DevOps, the single integrated team also takes responsibility for the activities on the right. Not only do they package the software artifact in readiness for release, but they are also responsible for the release and configuration itself.
Small, High Frequency, Deployments
Emphasizing the practice of releasing small-scale changes frequently into production, DevOps methodologies aim to minimize risks associated with larger deployments. Here are the key components and benefits of this approach:
Key Metrics for Small Deployments
-
Change Lead Time:
- Measures the duration from when a change is agreed upon to when it is implemented in production. The focus on shortening this time encourages smaller, more manageable changes that can be deployed faster.
-
Deployment Frequency:
- The rate at which deployments occur, potentially several times per day. Frequent deployments make the process a routine activity, reducing the perceived risk and complexity of deployments.
-
Deployment Duration:
- Tracks the time it takes to deploy a change. This metric tends to decrease as processes are refined and more aspects of the deployment are automated.
-
Change Failure Rate:
- Assesses the likelihood of a deployment causing a failure in the system. Smaller changes typically have a lower risk of causing significant issues, thereby improving system stability.
-
Mean Time to Recovery:
- Measures the time it takes to restore service after a failure. Efficient DevOps practices, including automated rollbacks, help reduce this time, ensuring quick recovery from any deployment-related issues.
Benefits of High Frequency Deployments
- Minimized Risk: Smaller changes entail less risk as they are easier to manage, test, and rollback if necessary.
- Rapid Detection and Remedy: Any defects introduced are likely to be minor and can be quickly identified and rectified.
- Increased Comfort with Deployment: Regular deployment cycles make the process familiar and less daunting for the team.
- Operational Efficiency: Automation in deployment processes not only speeds up the deployment but also enhances the overall operational efficiency.
DevOps Culture
In a mature DevOps environment, the deployment workflow is continuous, with changes being planned, designed, released, and monitored concurrently. This ongoing cycle contributes to a cumulative enhancement of the software system, often without users noticing daily changes but recognizing significant improvements over time.
Strategic Focus
While productivity and the value delivered by the software team are crucial, the primary focus in this approach is on reducing disruptions caused by releases. By breaking down releases into smaller increments of change, teams can ensure a smoother transition and less downtime, which in turn supports overall business continuity and user satisfaction.
This structured approach not only optimizes the deployment process but also aligns with broader business goals by ensuring continuous improvement and resilience in software delivery processes.
Consistent, Predictable Environments
Consistency across environments reduces the risks of unexpected behavior during later deployment stages, contributing to smoother transitions and higher reliability of software releases. This practice not only supports DevOps goals of rapid and continuous delivery but also strengthens overall software quality and user satisfaction.
Here’s a breakdown of standard environments and considerations for maintaining consistency.
Standard Environments
- Development: Where developers make and test changes. Often includes tools and settings optimized for debugging and rapid iteration.
- Quality Assurance (QA): Used to perform thorough testing and validation of the software before it moves into more critical stages.
- User Acceptance Testing (UAT)/Pre-prod: Mimics production to ensure the software meets business requirements and is ready for live deployment.
- Production (Prod): The live environment where the application is available to end-users.
Key Considerations
- Operating Systems: Both the type (flavor) and version (release) of operating systems should be consistent across environments to avoid compatibility issues.
- File System Layouts: Ensuring that file paths and permissions are identical across environments to prevent runtime errors related to file access.
- Supporting Services: Services like databases should be replicated accurately across environments to ensure interactions are consistent.
- Language Runtimes and Interpreters: The versions and configurations of programming language runtimes and interpreters need to be uniform to avoid discrepancies in behavior.
- Application Dependencies: Libraries and other dependencies must be the same in all environments to ensure consistent application performance.
Implementation Strategies
- Replication of Environments: All environments should replicate the production setup as closely as possible to minimize failures caused by environment-specific issues.
- Identical Deployment Processes: The deployment process should be the same for all environments. If a procedure works in UAT, it should work identically in production.
- Handling Sensitive Information: Differences such as passwords or API keys should be managed securely and appropriately, ensuring they are not exposed in less secure environments.
- Environment-Specific Configurations: While environments should be consistent, certain settings (like debug tools in development) need to be adjusted for performance and security in production. For example, a React application might use a development server in the dev environment but be served as a compiled JavaScript file via a production server like Nginx in production. This necessitates having intermediate QA environments where production-ready versions of the software are tested before moving to UAT.
Releases
As already noted, a critical aspect of DevOps is breaking large changes down into small incremental releases such that the impact of any one change on an application is minimised, along with the risk of introducing a defect, or even causing a system failure.
This means that each individual change should be thought of as a discrete “stepping stone” towards the ultimate goal of (for example) adding a new feature. Ideally, you only want to ever change one component at a time within a DevOps workflow. This may in some cases mean that you need to include code only on a temporary basis that allows the component to interact with either version of another component.
For example: Suppose you are working on a web application that comprises a RESTful web service for obtaining weather forecasts and a dependent (perhaps something that generates weather maps from the data provided by the RESTful API).
You have decided to redesign the API, which is a major change.
When you implement this, you could change both the API and the way the dependent service connects to it at the same time. However, this is risky because you are having to change both how the service is offered and consumed at the same time. Instead, you can implement a temporary feature flag in the mapping service that can test for the version of the RESTful API and process the resource appropriately.
Note that:
- Feature flags can be useful for handling when a new feature isn’t actually available yet. For example, the flag here could introduce an “unknown” marker into the map if rainfall is actually a new data item to be provided in the new version of the API.
- Feature flags are useful more generally because they force developers to think explicitly about what happens if an external resource provides data in an unexpected way. For example, having a general case to the feature flag in this code could allow the mapping service to behave robustly in production if other changes are made to the API that aren’t properly planned.
- It is important to clean up and remove feature flags once they are no longer required. This step should be explicitly included into the list of planned changes for the application. Uncontrolled use of feature flags can lead to lots of redundant code appearing in the code base.
Automated Deployment
Although DevOps can in principle be practiced manually, the real benefit of DevOps is best achieved when automated continuous integration is extended to release packaging and deployment.
There are numerous ways of doing this, but a common approach is to designate a particular branch in the repository as being for a production environment. When a change is merged into that branch then a special job is triggered that causes the production environment to be updated with the latest changes.
Direct from SCM
There are several ways to organise the deployment of new releases from an SCM. Perhaps the simplest is to run the build process directly in the production environment. In this case, the continuous integration runner accesses the production environment, pulls the latest version of the repository, stops the currently running version of the service, performs a build as per the CI script and then restarts the service.
While simple, this is not ideal, because:
- The production node has to have additional components installed to support the build process, such as compilers and test suites. This potentially increases the security exposure of the prod environment.
- The production node needs to have authentication credentials for the SCM and the SCM needs to have access to authentication credentials for the prod environment. In some organisations, a clear separation between dev and prod access is necessary.
- The service will be down during the rebuild process, which (as per CI good practice) might take up to 10 minutes. Even if the old release can be left running until build is complete, the build process is still consuming resources that might result in a degradation of service.
- The entire build process will need to be repeated for every environment the new release needs to be deployed on.
Direct from Release Repo
A better approach is to use a release repository to store the compiled artifacts prior to deployment. In this case, the CI process runs in an isolated environment and compiles the various software artifacts. These are then uploaded to a artifact repository, such as PiPy or Maven. Once this is completed a separate script gets run on the production environment.
Rather than building a new release, it simply takes a copy from the artifact repository. This is generally much more efficient and keeps all account credentials isolated.
Deployment Secrets Management
Continuous deployment procedures often involve providing secret information, such as passwords or secret tokens. These shouldn’t be stored in the source code repository, as this represents a security risk - once the repository has been cloned it could be unintentionally shared with others.
One approach to credential management is to store them as environment variables within the CI/CD infrastructure. This is okay for small scale deployments where you only need to manage a few secrets (a single deployment server, for example).
Monitoring in Dev Ops
In a Development and Operations organisation, responsibility for application and infrastructure monitoring is segmented. The ops team are responsible for maintaining and monitoring the underlying infrastructure, whilst the development team can implement application specific monitors. These application level instruments are likely to be used by the
This creates silos between different types of monitoring, their implementers and users. When faults are detected, these are initially diagnosed by the operations team, who may revert to the application team for guidance.
In a DevOps arrangement, the development team is responsible for implementing, maintaining and monitoring instrumentation across both the infrastructure and the application. The key benefit is that a single team gets instant real time feedback on the status of the service they are maintaining.
Monitoring can cover a wide variety of aspects of system healthiness. Measuring node liveness can give early warning about the potential for a cascade failure if a number of replicated nodes suddenly stop responding. Resource usage can also help a team to plan increasing the capacity of their infrastructure if resource limits are close to being reached.
User behaviour can also be indicative of problems (i.e. if all user interaction suddenly drops away) but can also point to opportunities for increased business value if particular features are identified as popular.
Teams can use a combination of off-the-shelf monitoring tools and customised application metrics to continuously observe their system and infrastructure.
One thing to be wary of is violating privacy policies or other regulations through monitoring. For example, logging data may contain records of personal information that is subject to GDPR.
Recovery Planning
Sometimes changes do still result in the introduction of defects. If these are not serious then it may be possible to fix the defect with a subsequent change. However, sometimes defects can cause serious failures, so a team needs to prepare for recovery and/or rollback of a change. This can involve a variety of activities.
Some of these can be automated, although some will need careful consideration. For example, the team may need to consider how to handle data records that have been added to a table after a migration that may not be compatible with the old format.
Mature DevOps teams will also periodically practice rollback and recovery operations within a replica of the production environment.
Chaos Engineering is a related software engineering approach that deliberately introduces failures into real software infrastructure to incentivise teams to build applications that are both robust to failures but also capable of rollback if needed.