Distributed System Fundamentals
What Is a Distributed System?
A distributed system can be defined in several ways:
-
Tanenbaum and van Steen: “A collection of independent computers that appears to its users as a single coherent system”
-
Coulouris, Dollimore and Kindberg: “One in which hardware or software components located at networked computers communicate and coordinate their actions only by passing messages”
-
Lamport: “One that stops you getting work done when a machine you’ve never even heard of crashes”
Motivations for Distributed Systems
- Geographic Distribution: Resources and users are naturally distributed
- Example: Banking services accessible from different locations while data is centrally stored
- Fault Tolerance: Problems rarely affect multiple locations simultaneously
- Multiple database servers in different rooms provide better reliability
- Performance and Scalability: Combining resources for enhanced capabilities
- High Performance Computing, replicated web servers, etc.
Examples of Distributed Systems
- Financial trading platforms
- Web search engines (processing 50+ billion web pages)
- Social media platforms supporting billions of users
- Large Language Models (trained across clusters)
- Scientific research (e.g., CERN with over 1 Exabyte of data)
- Content Delivery Networks (CDNs)
- Online multiplayer games
Fallacies of Distributed Computing
Eight classic assumptions that often lead to problematic distributed systems designs (identified at Sun Microsystems):
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- There is one administrator
- Transport cost is zero
- The network is homogeneous
- Topology doesn’t change
Key Aspects of Distributed System Design
- System Function: The intended purpose (features and capabilities)
- System Behavior: How the system performs its functions
- Quality Attributes: Core qualities determining success:
- Performance
- Cost
- Security
- Dependability
Challenges in Distributed Systems
Distributed systems introduce complexity in:
- Coordination
- Consistency
- Fault detection and recovery
- Security
- Performance optimization
-
Cloud Systems Quality Attributes
Quality attributes are non-functional requirements that determine the success of a cloud system beyond its basic functionality.
Core Quality Attributes
1. Performance
- Workload handling: Capacity to process the required volume of operations
- Efficiency: Resource usage in relation to output
- Responsiveness: Speed of response to user requests or events
- Throughput: Total amount of work accomplished in a given time period
- Latency: Time delay between action and response
2. Cost
- Build/deployment costs: Initial setup expenses
- Operational costs: Ongoing expenses to run the system
- Maintenance costs: Expenses for updates, fixes, and improvements
- Resource optimization: Efficient use of hardware, software, and human resources
- Scaling costs: Expenses related to growth or contraction
3. Security
- Access control: Prevention of unauthorized access
- Data protection: Safeguarding sensitive information
- Integrity: Ensuring data remains uncorrupted
- Confidentiality: Keeping private information private
- Compliance: Meeting regulatory requirements
4. Dependability
- Availability: Readiness for correct service
- Reliability: Continuity of correct service
- Safety: Freedom from catastrophic consequences
- Integrity: Absence of improper system alterations
- Maintainability: Ability to undergo repairs and modifications
Service and Failure Concepts
Correct Service vs. Failure
- Correct service: System implements its function as specified
- Failure: Deviation from the functional specification
- Not binary but exists on a spectrum from optimal to complete failure
Quality of Service (QoS)
- A measure of how well a system performs
- The ability to provide guaranteed performance levels
- Multiple dimensions: latency, bandwidth, security, availability, etc.
- Highly contextual and defined for specific applications
- Goal: Highest QoS despite faults at the lowest cost
Potential Failure Sources in Datacenters
Hardware Failures
- Node/server failures (crashes, timing issues, data corruption)
- Power failures (crashes, possible data corruption)
- Physical accidents (fire, flood, earthquakes)
Network Failures
- Router/gateway failures affecting entire subnets
- Name server failures impacting name domains
- Network congestion leading to dropped packets
Software and Human Factors
- Software complexity leading to bugs
- Misconfiguration and human error
- Security attacks (both external and internal)
Real-world Datacenter Failures
- 2008: Amazon S3 major outages affecting US & EU
- 2011: Amazon EBS and RDS outage lasting 4 days
- 2015: Apple service disruptions (iTunes, iCloud, Photos)
- 2016: Google Cloud Platform significant outage
- 2021: OVHcloud fire destroying datacenters in Strasbourg
Datacenter Failure Statistics
- 40% of servers experience crashes/unexpected restarts (Google)
- 57% of failures lead to VM migrations (Google)
- Hard drives cause 82% of hardware failures
- Power & Cooling are the most common cause of outages (71%)
- Over 60% of failures result in $100,000+ losses
Failures and Dependability
Understanding Failures, Errors, and Faults
The Fault-Error-Failure Chain
- Fault: Hypothesized cause of an error
- A defect in the system (e.g., bug in code, hardware defect)
- Not all faults lead to errors
- Error: Deviation from correct system state
- Manifestation of a fault
- May exist without causing a failure
- Examples: erroneous data, inconsistent internal behavior
- Failure: System service deviating from specification
- Visible at the service interface
- Caused by errors propagating to the service interface
- Examples: crash, incorrect output, timing violation
Fault Classification
Faults can be classified along multiple dimensions:
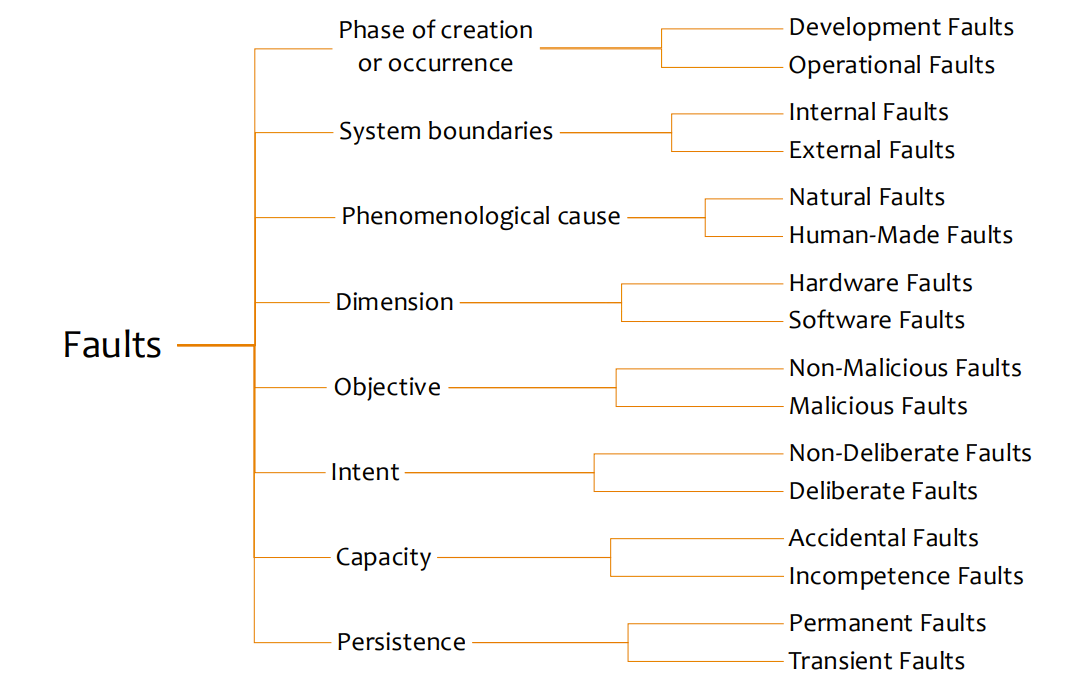
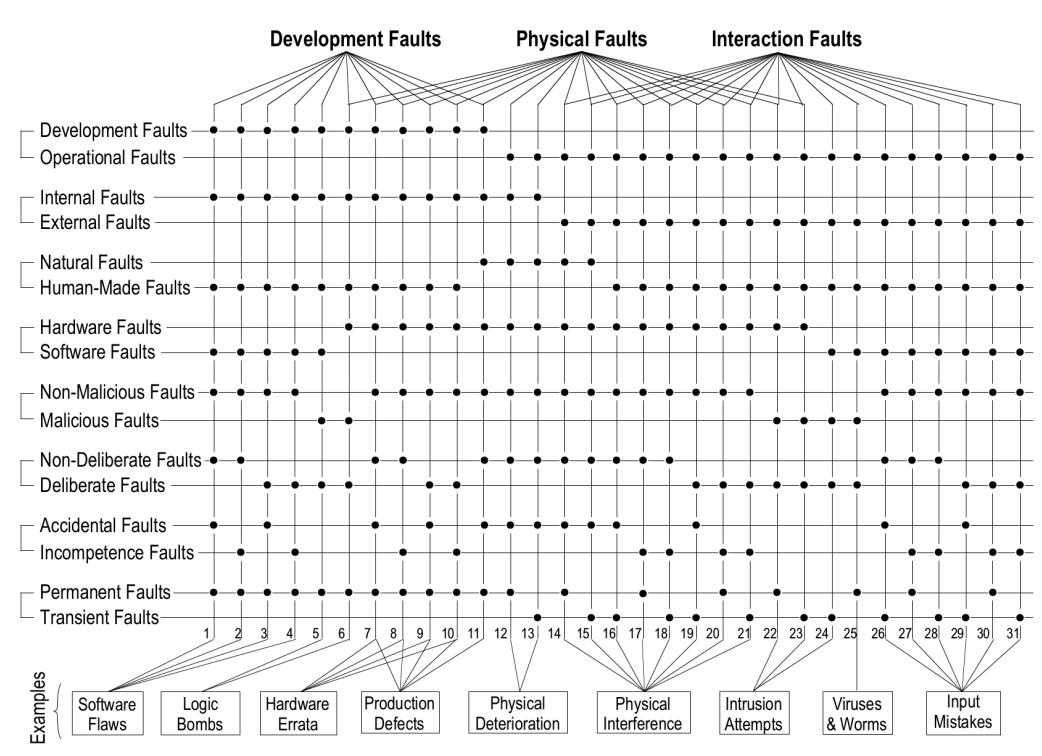
Phase of Creation or Occurrence
- Development Faults: Introduced during system development
- Operational Faults: Occurring during system operation
System Boundaries
- Internal Faults: Originating from within the system
- External Faults: Originating from outside the system
Phenomenological Cause
- Natural Faults: Caused by natural phenomena
- Human-made Faults: Resulting from human actions
Intent
- Non-malicious Faults: Without harmful intent
- Malicious Faults: With harmful intent (attacks)
Capability/Competence
- Accidental Faults: Introduced inadvertently
- Incompetence Faults: Due to lack of skills/knowledge
Persistence
- Permanent Faults: Persisting until repaired
- Transient Faults: Appearing then disappearing
Failure Spectrum
Failure isn’t binary but exists on a spectrum:
- Optimal Service: Meeting functional requirements and balancing all quality attributes
- Partial Failure: Some parts of the system fail while others continue
- Degraded Service: System functions but with reduced performance
- Transient Failure: Temporary interruption with automatic recovery
- Complete Failure: System becomes unresponsive or produces incorrect results
Dependability Attributes
Dependability Tree
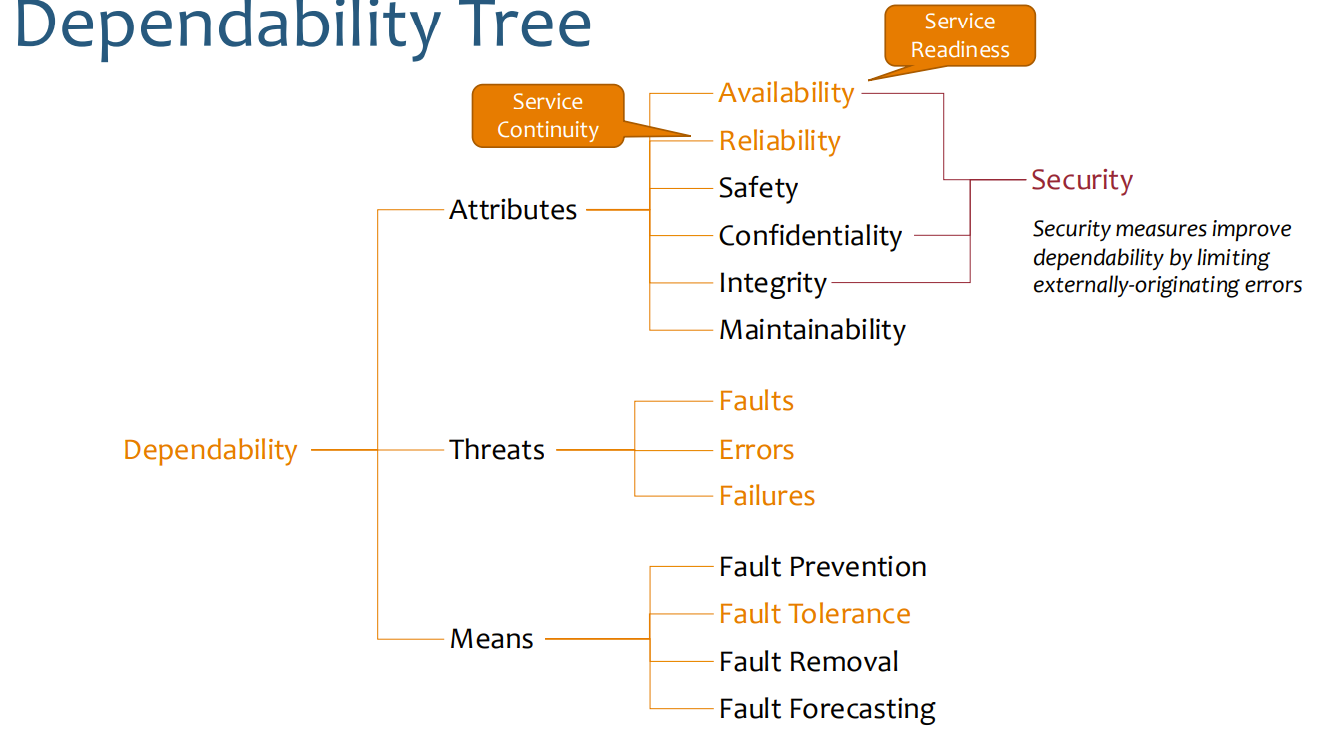
-
Attributes
- Availability: Readiness for correct service
- Reliability: Continuity of correct service
- Safety: Freedom from catastrophic consequences
- Confidentiality: Absence of unauthorized disclosure
- Integrity: Absence of improper system alterations
- Maintainability: Ability to undergo repair and evolution
-
Threats
- Faults
- Errors
- Failures
-
Means
- Fault Prevention
- Fault Tolerance
- Fault Removal
- Fault Forecasting
Availability and Reliability
Distinction
- Availability: System readiness for service when needed
- Measured as percentage of uptime
- Focused on accessibility
- Reliability: System’s ability to function without failure over time
- Measured as Mean Time Between Failures (MTBF)
- Focused on continuity
Examples
- System with 99.99% availability but produces incorrect results occasionally: High availability, low reliability
- System that never crashes but shuts down for maintenance one week each year: High reliability, lower availability (98%)
- Fault: Hypothesized cause of an error
High Availability
Importance of High Availability
Business Impact
- Downtime can be extremely costly in today’s interconnected world
- Minimizes business disruptions, maintains customer satisfaction, and protects revenue
User Expectations
- Users expect 24/7 service availability
- Poor availability damages reputation and user trust
Critical Systems
- Essential for healthcare, finance, emergency services, and other critical infrastructure
- Directly impacts safety and well-being
Availability Levels (The “9’s”)
Availability Downtime per Year Downtime per Month Downtime per Week 90% (one nine) 36.5 days 72 hours 16.8 hours 99% (two nines) 3.65 days 7.2 hours 1.68 hours 99.9% (three nines) 8.76 hours 43.8 min 10.1 min 99.99% (four nines) 52.6 min 4.38 min 1.01 min 99.999% (five nines) 5.26 min 25.9 s 6.06 s 99.9999% (six nines) 31.56 s 2.59 s 0.61 s 99.99999% (seven nines) 3.16 s 259 ms 61 ms - Each additional “9” represents an order-of-magnitude reduction in downtime
- Higher availability systems require exponentially more effort and resources
Means to Achieve Dependability
Fault Prevention
- Approach: Prevent occurrence of faults proactively
- Techniques:
- Suitable design patterns
- Rigorous requirements analysis
- Formal verification methods
- Code reviews and static analysis
Fault Tolerance
- Approach: Design systems to continue operation despite faults
- Techniques:
- Redundancy in components and systems
- Error detection mechanisms
- Recovery mechanisms
Fault Removal
- Approach: Identify and reduce existing faults
- Techniques:
- Early prototyping
- Thorough testing
- Static code analysis
- Debugging
Fault Forecasting
- Approach: Predict future fault occurrence and consequences
- Techniques:
- Performance monitoring
- Incident report analysis
- Vulnerability auditing
Foundations of High Availability
Fault Tolerance
Key strategies for fault tolerance:
- Error detection
- Failover mechanisms (error recovery)
- Load balancing
- Redundancy/replication
- Auto-scaling
- Graceful degradation
- Fault isolation
Error Detection in Data Centers
- Monitoring: Collecting metrics like CPU, memory, disk I/O
- Heartbeats for basic health indication
- Threshold monitoring for overload detection
- Telemetry: Analyzing metrics across servers
- Identifying patterns and anomalies
- Detecting potential security threats
- Observability: Understanding internal state through outputs
- Log analysis
- Tracing communications through the system
Circuit Breaker Pattern
- Inspired by electrical circuit breakers
- States: Closed (normal), Open (after failures), Half-open (testing recovery)
- Prevents overload of failing services
- Fails fast rather than degrading under stress
Hardware Error Detection
- ECC Memory: Detects and corrects single-bit errors
- Redundant components: Multiple power supplies, network interfaces
Real-world Examples
- Uber’s M3: Platform for storing and querying time-series metrics
- Netflix’s Mantis: Stream processing of real-time data for monitoring
Failover Strategies
Active-Passive Failover
- Active: Primary system handling all workload
- Passive: Idle standby system synchronized with active
- Failover: When active fails, passive becomes active
- Variations:
- Cold Standby: Needs booting and configuration
- Warm Standby: Running but periodically synchronized
- Hot Standby: Fully synchronized and ready to take over
Active-Active Failover
- Multiple systems simultaneously handling workload
- Load balancer distributes traffic
- When one system fails, others take over
- Provides immediate recovery with no downtime
Decision Factors for Failover Strategy
- State management and consistency requirements
- Recovery Time Objective (RTO)
- Cost constraints
- Operational complexity
Modern Cloud Architectures - Microservices
Evolution from Monolith to Microservices
Traditional monolithic applications face challenges as they grow:
- Increasingly difficult to maintain
- Hard to scale specific components
- Complex to evolve with changing requirements
- Technology lock-in
Microservices architecture emerged as a solution to these challenges.
What Are Microservices?
Microservices architecture is an approach to develop a single application as a suite of small services, each:
- Running in its own process
- Communicating through lightweight mechanisms (often HTTP/REST APIs)
- Independently deployable
- Built around business capabilities
- Potentially implemented using different technologies
Key Characteristics of Microservices
- Loose coupling: Services interact through well-defined interfaces
- Independent deployment: Each service can be deployed without affecting others
- Technology diversity: Different services can use different technologies
- Focused on business capabilities: Services aligned with business domains
- Small size: Each service focuses on doing one thing well
- Decentralized data management: Each service manages its own data
- Automated deployment: CI/CD pipelines for each service
- Designed for failure: Resilience built in through isolation
Microservices Architecture Components
A typical microservices architecture includes:
- Core Services: Implement business functionality
- API Gateway: Provides a single entry point for clients
- Service Registry: Keeps track of service instances and locations
- Config Server: Centralized configuration management
- Monitoring and Tracing: Distributed system observability
- Load Balancer: Distributes traffic among service instances
Advantages of Microservices
-
Independent Development:
- Teams can work on different services simultaneously
- Faster development cycles
- Smaller codebases are easier to understand
-
Technology Flexibility:
- Each service can use the most appropriate tech stack
- Easier to adopt new technologies incrementally
-
Scalability:
- Services can be scaled independently based on demand
- More efficient resource utilization
-
Fault Isolation:
- Failures in one service don’t necessarily affect others
- Easier to implement resilience patterns
-
Maintainability:
- Smaller codebases are less complex
- Easier to understand and debug
- New team members can become productive faster
-
Reusability:
- Services can be reused in different contexts
- Example: Netflix Asgard, Eureka services used in multiple projects
Disadvantages of Microservices
-
Complexity:
- Increased operational overhead with more services to manage and monitor
- Distributed debugging challenges - tracing issues across multiple services
- Complexity of service interactions and dependencies
-
Performance Overhead:
- Latency due to network communication between services
- Serialization/deserialization costs
- Network bandwidth consumption
-
Operational Challenges:
- Microservice sprawl - could expand to hundreds or thousands of services
- Managing CI/CD pipelines for multiple services
- End-to-end testing becomes more difficult
-
Failure Patterns:
- Interdependency chains can cause cascading failures
- Death spirals (failures in containers of the same service)
- Retry storms (wasted resources on failed calls)
- Cascading QoS violations due to bottleneck services
- Failure recovery potentially slower than in monoliths
Microservice Communication
Synchronous Communication
- REST APIs (HTTP/HTTPS): Simple request-response pattern
- gRPC: Efficient binary protocol with bidirectional streaming
- GraphQL: Query-based, client specifies exactly what data it needs
Pros:
- Immediate response
- Simpler to implement
- Easier to debug
Cons:
- Tight coupling
- Higher latency
- Lower fault tolerance
Asynchronous Communication
- Message queues: RabbitMQ, ActiveMQ
- Event streaming: Apache Kafka, AWS Kinesis
- Pub/Sub pattern: Google Cloud Pub/Sub
Pros:
- Loose coupling
- Better scalability
- Higher fault tolerance
Cons:
- More complex to implement
- Harder to debug
- Eventually consistent
Glueware and Support Infrastructure
Microservices require substantial supporting infrastructure (“glueware”) that often outweighs the core services:
- Monitoring and logging systems
- Service discovery mechanisms
- Load balancing services
- API gateways
- Message brokers
- Circuit breakers for resilience
- Distributed tracing tools
- Configuration management
According to the Cloud Native Computing Foundation’s 2022 survey, glueware now outweighs core microservices in most deployments.
Avoiding Microservice Sprawl
To prevent excessive complexity with microservices:
-
Start with a monolith design
- Gradually break it down into microservices as needed
- Identify natural boundaries and avoid over-decomposition
-
Focus on business capabilities
- Design around clear business purposes rather than technical functions
-
Establish clear governance
- Define guidelines and best practices for microservice development
- Create standards for naming conventions, communication protocols, etc.
-
Implement fault-tolerant design patterns
- Timeouts, bounded retries, circuit breakers
- Graceful degradation