Abstract
We want everyone to send as fast as possible naturally, however if everyone sends too fast and we don’t have enough bandwidth, etc., we will clog the network and therefore we need to not send too fast so as to ruin the network for everyone else
The TCP network is complex, and highly optimized, but still faces issues on how to handle congestion. Two main approaches:
- Loss Based (Using Packet Loss as a measure of Network Capacity
- TCP Reno/Cubic
- Delay Based (Using RTT delay as a measure)
- TCP Vegas(Barely Used)/BBR
Packet Loss is used as a congestion signal as: In congested networks, when packets make it to an intermediate device that has a full queue, it will simply throw away the packet
For Sending Rates: (additive increase/multiplicative decrease)
- Increase Rate slowly.
- Decrease Rate quickly
Key Principles:
Packet Loss as a Congestion Signal
Data flows from source to destination through a series of IP routers.
Routers have two functions:
- Routing: receive packets, determine appropriate route to destination
- Forwarding: enqueue packets on outgoing link for delivery
- If packets are coming in faster than they can be forwarded, a queue arises, and these queues have a maximum size, so if the queue hits the maximum size, the next packets are discarded.
- Queues shrink if packets are forwarded faster than they arrive
- Queues grow if packets arrive faster than they can be forwarded
- Queues have maximum size → **packets discarded if the queue is full **
- Congestion control can use this packet loss as a congestion signal
Conservation of Packets
- Acknowledgements returned by receiver
- Send one packet for each acknowledgement received
- Total number of packets in transit is constant Internet
- System is in equilibrium; queues neither increase nor decrease in size
- ACK clocking – each acknowledgement “clocks out” the next packet
- Automatically reduces sending rate if network gets congested and delivers packets more slowly
AIMD Algorithm
Sending rate follows additive increase, Sender multiplicative decrease (AIMD) algorithm
- Start slowly, increase gradually to find equilibrium Internet
- Add a small amount to the sending speed each time interval without loss
- For a window-based algorithm each RTT, where typically
- Respond to congestion rapidly
- Multiply sending window by some factor each interval loss seen
- For a window-based algorithm each RTT, where $β = 1/2£ typically
- Faster reduction than increase → stability; TCP Reno
Stability is more important than max speed, or max capacity use, as a fast network that fails frequently is not useful
Sliding Window
Sliding Window Protocols
Sliding window protocols improve link utilization using a congestion window – number of packets to be sent before an acknowledgement arrives.

In this example, the window size is six packets → acknowledgement for packet 6 arrives just in time to release packet 7 for transmission
Each returning acknowledgement for new data slides the window along, releasing next packet for transmission → if window sized correctly, each acknowledgement arrives just in time to release next packet This means that ideally just as/ just after the last packet comes in, the acknowledgement for the first packet comes in.
What is the optimal size for the window? bandwidth × delay of path → but neither is known to the sender
The delay will be changed by the slowest link, but we don’t know our path. So we have to guess:
How to choose initial window size, ?
Link to original
- No information → need to measure path capacity
- Start with a small window, increase until congestion
- = 1 packet per round-trip time (RTT) is safe
- Start at the slowest possible rate, equivalent to stop-and-wait, and increase
- = 3 packets per RTT - **Traditional TCP Reno approach **
- = 10 packets per RTT - Modern TCP implementations [RFC 6928]
10 is most likely too low for modern first world countries, most likely too high for third world countries
- Compromise between safety and performance – measurements show this is generally safe at present
- Expect to gradually be increased as average network performance improves
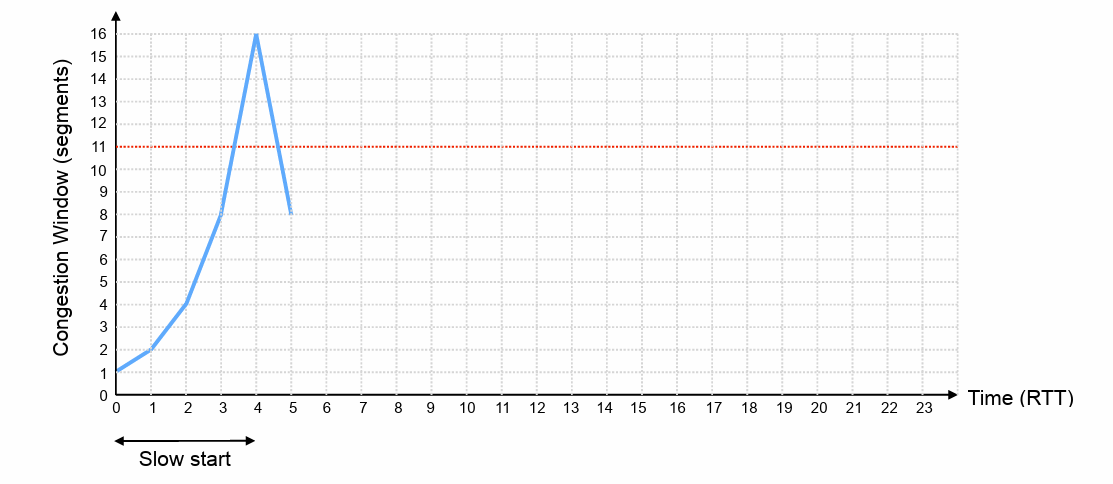
Slow Start
Slow Start
Deceptively named:
- Assume = 1 packet per RTT – slow start to connection
- It will be = 3 or = 10 in practice, but using = 1 makes the example simpler…
- Rapidly increase window until network capacity is reached
- Each acknowledgement for new data increases congestion window, W, by 1 packet per RTT → congestion window doubles each RTT
- If a packet is lost, halve congestion window back to previous value and exit slow start
Link to original
TCP Reno TCP Cubic TCP Vegas TCP BBR
Explicit Congestion Notification
Abstract
TCP has inferred congestion through measurement • TCP Reno and Cubic → packets lost when queues overflow • Problematic because it increases delay • Problematic because of non-congestive loss on wireless links • TCP Vegas → increase in delay as queues start to fill • Conceptually a good idea, but difficult to deploy when competing with TCP Reno and Cubic
Also used in QUIC & RTP
Question
Why not have the network tell TCP congestion is occurring?
• Explicit Congestion Notification (ECN) field in IP header • Tell TCP to slow down if it’s overloading the network
Implementation:
Part 1
Sender sets ECN bits when transmitting:
- → Doesn’t support ECN
- → Supports ECN
If congestion occurs: Router sets ECN bits to
The receiver receives these ECN bits as and notices the congestion
Part 2
ECN Echo (ECE) field in TCP header allow it to signal this back to the sender:
- → Default, ignore
- → Congestion occurred on send to receiver.
Part 3
The sender on their next packet will send a CWR confirmation
- → Default, ignore
- → ECE received
Dump
The TCP networks (Reno/Cubic) use the amount of Packet Loss to indicate the usage of network capacity
Some other approaches are delay based congestion control: Used by TCP Vegas (Nobody uses, was a super early model) as well as TCP BBR (Google Product, not very effective, but used by “fan boys” - Colin)
TCP Reno is the main topic of discussion, many many other standards attempt to improve it, but Cubic is the only model that has any kind of widespread adoption